汽車商業(yè)評論2024-05-14 12:16

![]()


撰文?/ 張霖郁
編輯?/ 黃大路
設計?/ 師 超
2022年開始由OpenAI推出的ChatGPT3的驚人表現(xiàn)迅速讓人工智能成為全社會的熱點。
這種熱度不只是表現(xiàn)在輿論場,全球資本市場真金白銀的巨額投入以及英偉達作為人工智能時代核心廠商市值的飆升都宣告了一個新時代的即將來臨。
軒轅之學巨浪4期學員韓東正處于這一大風口,作為NYONIC的創(chuàng)始人,他公司的主營業(yè)務是幫助企業(yè)建模型工廠,訓練模型,賦能應用,為汽車行業(yè)鏈條上的企業(yè)賦能。
韓東本人從事人工智能相關工作約在20年前,當時是作為學生身份。他2004年至2008年就讀德國馬克思普朗克研究院計算機所,專業(yè)是計算機科學。馬克思普朗克研究院計算機所是歐洲排名第一陣營的計算機科研院所。
“2012年之前深度學習是計算機領域一個沒人愿意碰的東西,堅持下來的人并不多。當時沒有人需要AI博士,大家其實都找不到工作。”韓東說。
2024年3月17日,軒轅之學巨浪4期第六模塊“汽車營銷新思維”課程的第二天下午,按既往慣例,學員進行分享,每次大概2-3人。韓東作為第一個學員進行分享。

“我是AI科班出身的從業(yè)者,二十多年前大學一年級就開始在德國人工智能研究中心做NLP的研究助理工作,也做了計算機視覺和機器學習的研究,十多年前就在ICCV上發(fā)表文章。后面經過了德國創(chuàng)業(yè)孵化器的熏陶叫ROCKET INTERNET,這是一家孵化了眾多獨角獸公司的孵化器。”
他說2020年之前,深度學習訓練出來的Chatbot的水平和1960年的水平基本沒有本質區(qū)別,過去六七十年一直沒有什么大的變化。前幾十年很少有人相信這件事能做成,覺得深度神經網絡是一門玄學。但GPT3讓大家第一次看到了所謂的涌現(xiàn)能力,之前沒有訓練模型做這件事情,但模型自己就會。你會發(fā)現(xiàn)訓練出來的模型可以做無數(shù)件它沒有遇到過的事情,這一直是大家夢寐以求的事情。
此次分享會,除了韓東,中科創(chuàng)達智能網聯(lián)產品中心總經理馬強也進行了分享。
馬強畢業(yè)于人民大學EMBA,他在智能網聯(lián)汽車電子軟件行業(yè)超過15年以上。他曾在東軟集團任職,2015年加入中科創(chuàng)達。
以手機軟件起家的中科創(chuàng)達隨著2015年智能座艙概念的興起成功進入了座艙領域,公司營收也由此進一步增長。但馬強說近幾年中科創(chuàng)達也正經歷轉型。他說目前操作系統(tǒng)廠商和芯片廠商,除了進行標準系統(tǒng)的開發(fā)外,也同時進入了定制化業(yè)務,這對中科創(chuàng)達的原有業(yè)務產生了一定影響。這是當前他們的挑戰(zhàn)之一。
另外,主機廠的降本要求與日俱增。他說最開始做高通8155芯片時,車企一個座艙平臺的研發(fā)預算大概在大幾千萬元,現(xiàn)在已降到幾百萬元。
以下是他們兩位的實錄摘要。
2012年之前深度學習是計算機領域沒人愿意碰的東西,做深度學習堅持下來的人并不多。OpenAI GPT2出來的時候效果非常糟糕,沒有人把它當學術來對待,但是GPT3出來讓所有人都驚呆了,大家覺得這個方向真的可以走通。這也導致現(xiàn)在這一領域的人才數(shù)極少,大部分被OpenAI和谷歌兩家公司卷走了,基本上來講,你很難吸引這些人回到國內的公司。
現(xiàn)在大家的共識是AI將重構每個國家的戰(zhàn)略、行業(yè)、應用。我們過去這一年跟美國、跟歐洲很多這方面的專家打交道時發(fā)現(xiàn),很明顯AI在大國競爭當中扮演非常重要的角色。

回到具體行業(yè)當中,我給大家說一下哪些公司真正從當中獲益了?
最大的三個機會,第一個在GPU領域,大家都知道英偉達過去一年通過大模型他們非常的飛速增長,包括毛利、凈利潤,這些都非常的驚人。第二個大的商業(yè)機遇在云計算領域,因為所有這些AI模型對外提供服務的時候,都得在云上對外提供。第三個可以從兩個角度來說,一個是行業(yè)角度,因為各行各業(yè)后面都會被AI賦能。我們日常生活當中可能用到最多的三個端側,一個是PC電腦筆記本、第二個是手機、第三個是汽車。

中國在汽車這個場景下是一個無法忽略的市場,因為占領全球三分之一。AI比拼主要還是中國和美國之間,車的大模型這一塊美國公司很難去做到全球領先,因為美國可能連相應的客戶都沒有,車廠也只有特斯拉一家。所以這一塊我有一個信念,全球最領先的汽車行業(yè)的大模型公司肯定會來自于中國。

我們說行業(yè)大模型到底是什么意思?它不是說我們做一個行業(yè)大模型可以解決汽車行業(yè)所有的事情,而是去跟通用基礎大模型進行區(qū)分。在行業(yè)大模型基礎上,更多去跟汽車行業(yè)具體場景結合,在不同的環(huán)節(jié)加入額外的高質量數(shù)據得到額外的能力去解決具體的事情,就好像數(shù)字員工,有些做專業(yè)文檔寫作,有些做軟件開發(fā)和測試。
我們自己在這一年主要做了兩件事情:搭建了一個訓練大模型的模型工廠,包括整個數(shù)據處理,訓練和推理的基礎設施,同時有能力去給各個客戶或者合作伙伴輸出不同的行業(yè)模型或場景模型。

整個模型訓練的工程過程,一開始有非常大量的數(shù)據,很多是公開數(shù)據,如果說訓練一些行業(yè)模型,場景模型可能會有些企業(yè)數(shù)據。公開數(shù)據會在模型工廠里有整個數(shù)據的預處理,數(shù)據混合(data mix),ETL的管道,同時不斷的有一個評估的過程,再去做訓練。但是因為數(shù)據量太大了,深度神經網絡又不是可解釋的東西,所以就造成了大模型特別難訓練,因為模型參數(shù)太多,數(shù)據量太多,單純訓練就很難,把那么多GPU連起來也很難,高算力的GPU包括A100或者H100包括昇騰等,這些都是半成品,現(xiàn)在還處在不斷的在往前迭代的產品,問題非常非常多。
我這邊舉個核心挑戰(zhàn)的例子。超大規(guī)模的數(shù)據處理,GPU算力利用率。算力的利用率這邊有一個對標的數(shù)字就是GPT4大概在2萬多個A100的進行了90-100天的訓練,算力利用率只有33%,就是說這么長時間很多機器并不是真正在做訓練的。整體的花費,跑一次大概在6千萬美金,跑一次是什么概念?這是成功的一次,但在之前至少做的實驗數(shù)目整個成本可能是10倍-50倍之間。GPT4也比較貴,它本身是萬億參數(shù)的模型,本身就非常復雜難收斂,包括GPU太多時候要保證它的穩(wěn)定性也更難。
在超大規(guī)模數(shù)據處理這一塊,我們在基礎設施上面希望能解決一些問題,讓我們后續(xù)訓練高效。基座模型基礎上如果進行重新的預訓練或者說繼續(xù)訓練,我們要保證數(shù)據加進去的時候不是從頭開始,而是可以繼續(xù)收斂我的loss曲線,不同的功能點、不同的指標能夠同時不斷的去收斂,就這件事情非常難做到。
但是做到之后,取得的效果有點像可能訓練第一個模型花了100塊,再訓練第二個模型在處理數(shù)據的時候可能只需要花1塊錢,但是如果沒有這個東西,可能第一個模型花100塊,第二個模型還是花100塊,再往下整個從經濟學上或者跟服務客戶的時候這個賬就算不過來了。
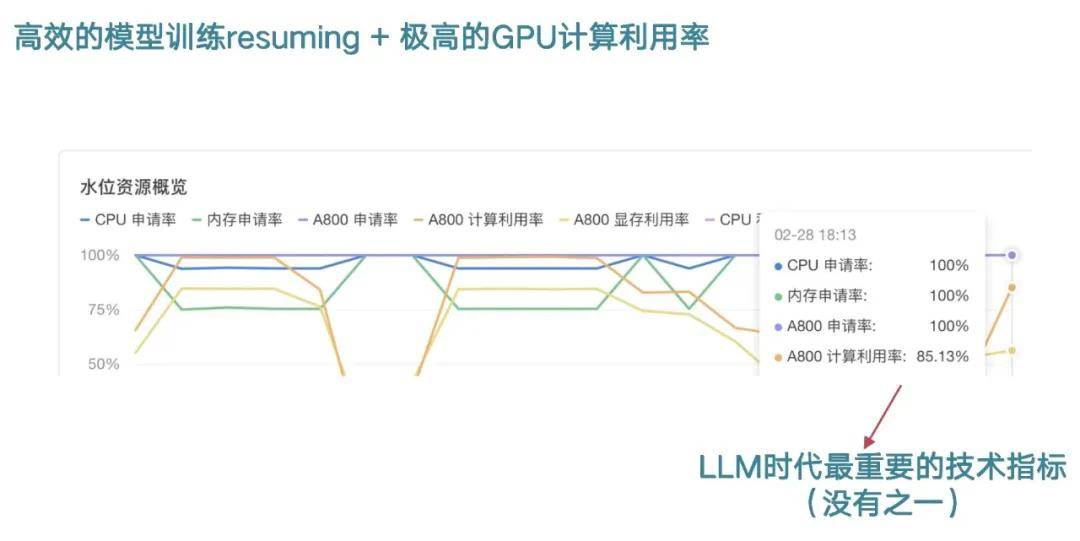
第二個是GPU利用率,包括模型訓練中斷怎么再接起來?一開始訓練中斷,解決問題經常要解決一兩天甚至兩三天才能讓它繼續(xù)訓練,但現(xiàn)在我們已經把這個時間從一兩天、兩三天降到一到兩分鐘,這對于整個的成本改變非常大。
在整個GPU的計算利用率上面,我們剛才也看到包括OpenAI當時做GPT4,整個計算利用率30%多,萬卡集群上目前為止也沒有人可以做到更好。我們目前數(shù)百張卡的集群,計算利用率達到85%,遠遠超過業(yè)界平均水平,這個到最后就是非常大的影響成本的指標,因為這個行業(yè)需要不斷的去訓練各種參數(shù)規(guī)模的模型。
我們也摸索了和客戶共同創(chuàng)新的方式,一般會先做可行性研究包括POC,然后具體場景的智能化改造,這個市場就很大了,各個公司都有AI賦能的場景。
我們有幾個具體的客戶,這是幫助一家國際的Tier1來解決設備維修問題,它有報警之后會自動出來維修的建議。過去維修的建議它的準確率是比較低,所以無法真正讓工人很有效的把它使用起來,但我們通過大模型,很快的幫它把故障識別率做到90%,而過去只有10%,這個工具就變得真正切實可用了。

質量標準問答也是類似的Q&A系統(tǒng),在做這件事情的時候,企業(yè)內部有非常大量的數(shù)據,但這些大量的數(shù)據很多都是非結構化的、分散的,散落在各個地方,過去并沒有很好的方法能夠把這些文檔、過去的知識、數(shù)據引入到AI模型當中來。但現(xiàn)在大模型的能力,它不需要標注這些訓練的數(shù)據,你只要能夠把它一起收集起來,把它放進來,做一定的預處理和數(shù)據混合,我們自己還只是語言模型,所以我們在做視覺訓練時,包括流程圖我們用其他多模態(tài)模型的接口,轉化為文本來使用,通過大模型真正可以把它的知識很好的聯(lián)系起來,讓助手從過去10%的準確率提高到了80%。
第二個在汽車軟件測試這一塊,我們知道軟件測試它有很多工具,但中途也會有很多人類專家介入的環(huán)節(jié),人類專家介入的是什么?就是在理解人類的語言,然后做邏輯推理、分拆、計劃下一步應該怎么做然后再去執(zhí)行。
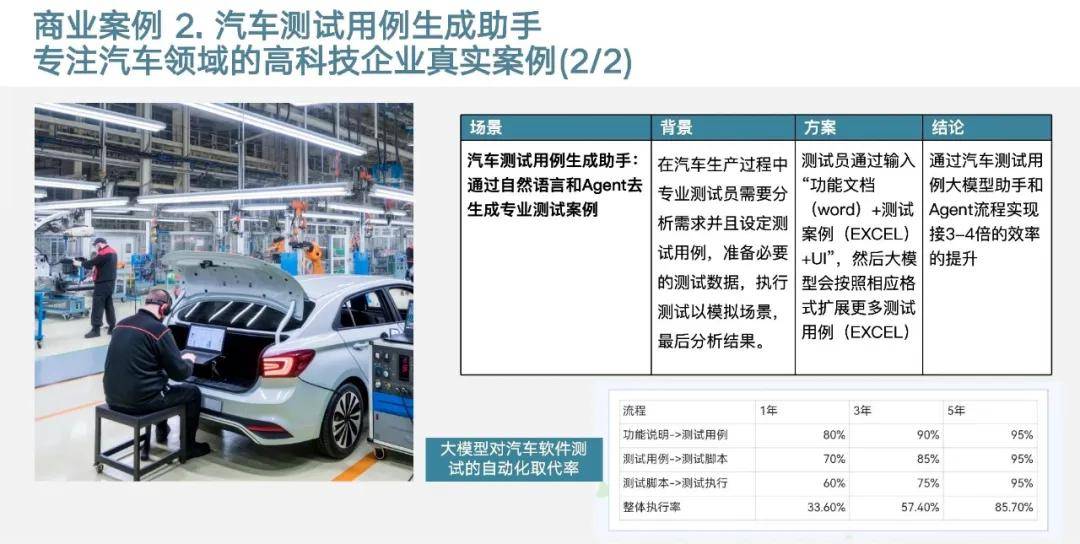
牽扯到這些語言的理解都是可以用大模型來做的,我們這邊是用大模型和Agent把整個專業(yè)的測試樣例去做自動化的生成,光在這一步大概有三、四倍的提升。整個這一塊我們會發(fā)現(xiàn)只要過去有人類專家介入的工作流,或多或少在未來都可以用AI+Agent去把它部分取代甚至于完全的取代,它就形成端到端自動化,一旦端到端自動化就解決了非常多的問題,成本也可以大幅度降低。

我們差不多20個人左右做了這件事情。我們經常說到一個觀點,這個行業(yè)在初期不配招太年輕的工程師,因為我們每個人的成本確實很高,更貴的是你要給他們配算力,這方面如果你用錯一個人,會浪費很多錢,浪費掉的是算力。

我們公司是2008年成立的,公司創(chuàng)業(yè)時是基于Linux手機設備,包括手持導航設備還有手持特殊的終端設備。
公司最開始成立時是和中科院計算機研究所合作,所以叫中科創(chuàng)達,最開始做Linux操作系統(tǒng)的。

2009年,谷歌發(fā)布了1.0版的安卓操作系統(tǒng),當時處于功能機向智能機轉化的時間節(jié)點,我們公司因之前有操作系統(tǒng)的背景,所以也在安卓系統(tǒng)上做了很多前瞻的預研。正好那個時間點很多手機廠商想轉型,自己沒有這個能力,于是就找到了我們。
我們公司是一個戰(zhàn)略導向型公司,基本上每一步都踩在了時代變革的機會點,也成就了后續(xù)的快速增長,很大程度都是抓住時代契機,不完全是我們人為的因素。
2010年之后,移動互聯(lián)網興起了,我們內部討論,是不是要改做移動互聯(lián)網?最后結論是不做,后來確實有很多同樣的友商都在做移動互聯(lián)網,之后都死掉了,這證明了要清楚認識自己的核心競爭力在哪里的重要性。我們的核心競爭力就在嵌入式操作系統(tǒng)技術,所以所有業(yè)務的擴展都圍繞著這個點來做的,專注在自己擅長的領域才能成功。

后面到2015年就上市了,這個時間點又迎來了一個浪潮。
汽車行業(yè)從傳統(tǒng)普通的娛樂控制器即IVI轉成智能座艙的概念,原來可能只有DA或者叫IVI和儀表是分離的,從2015年開始智能座艙的概念就興起了。這個時間節(jié)點,因為安卓系統(tǒng)進入汽車同時高通在這個里面逐漸越來越高的市占率,我們也借著這個浪潮又帶來一撥增長。
后續(xù)成立合資公司,達成各種合作,這也是順勢而為。
最后一個節(jié)點,從Smart to intelligent,我們開始裂變,逐漸把自己的業(yè)務范圍快速的擴張以及跟行業(yè)生態(tài)綁定關系逐漸建立起來。公司經歷了這四個階段,主要業(yè)務范圍包括智能終端、智能汽車、智能物聯(lián)網還有人工智能AI,我所在的是智能汽車板塊。
汽車大模型應用基本是兩個方向,一個方向是傳統(tǒng)語言模型方面的補足,以前我們用的語音模型都無法100%實現(xiàn)你的語言指令,始終達不到100%,你差一個關鍵詞它就聽不懂,以前是這樣的。另外也沒有上下文關聯(lián)的能力,比如我說我要去天安門,你下一步就問它旁邊有什么好吃的,它就不會了。但如果你用大語言模型,它可以幫你把上下文穿起來,相當于跟機器的交流更加人性化。
第二個方向是索引,在這里面可以把你以前的知識庫,把這些數(shù)據給它有機的組成起來。你可以很容易的通過大模型去索引它,幾乎它所有在車里的應用基本是基于這兩個維度的擴展。
講講我們公司的合資情況。
首先是收購的公司,芬蘭的RIGHTWARE,4.6億元人民幣。我們跟高通有兩家合資公司,一家是自動駕駛領域的,還有一家做物聯(lián)網相關領域的;和地平線的合資公司,是前年成立的;我們跟主機廠跟吉利等都有合資公司。

我們現(xiàn)在遇到什么問題?
首先說產業(yè)和市場的現(xiàn)狀。座艙行業(yè)或者汽車軟件研發(fā)的行業(yè)其實非常卷,主機廠的降本要求與日俱增,我們最開始做8155芯片時,一個座艙平臺能做到大幾千萬的研發(fā)費用,現(xiàn)在只有幾百萬的研發(fā)費用,數(shù)量級都不太一樣了。
主機廠為了降本,現(xiàn)在逐漸改變了競標模式,以前經常遇到的方式是技術和采購兩方面,技術先打一個分,采購依據你的價格也有個規(guī)則打一個分,兩個分加起來誰最高誰就能中標。
如果說我們對技術這一塊比較領先,技術分就會比較高,采購相關的,如果你的價格不是那么有競爭力,其實也是能拿到的。現(xiàn)在客戶逐漸轉變了策略,變?yōu)榧夹g選三家合格的,最后只看價格。
第二,因為主機廠很多都自研,今天的安卓也在說要自研,很多主機廠號稱自己要全棧自研。我們這個行業(yè)的友商很多也是因為有上市需求,所以它要收入,另外有一些生存的壓力,所以基本上都在做破成本價的競標,業(yè)務競爭非常的慘烈。

第三由于最近行業(yè)比較火熱,有很多核心人才被挖,為了保留核心人才只能說給額外的待遇,類似于股權之類的,人員成本也逐年上升。



第四是業(yè)務轉型。最開始他們的芯片、操作系統(tǒng),無論是高通的芯片或者安卓的操作系統(tǒng),它里面都是標準的系統(tǒng),你想做定制化開發(fā)是需要巨大的開發(fā)工作量的,需要很多人力在里面,對于我們這種公司,在這里是應運而生的,我們就是做標準操作系統(tǒng)和用戶需求之間的gap,無論是操作系統(tǒng)廠商還是芯片公司,他們從下面往上逐漸擠壓我們的生存空間,所以這一塊也是一個很大的風險。
 京公網安備 11010802028547號
京公網安備 11010802028547號
 購物車
購物車






