駱軼琪2024-03-11 07:46

![]()

隨著全球云計算巨頭紛紛提出自研AI芯片計劃,各類型計算產業(yè)鏈公司都迎來巨大發(fā)展機會。
雖然目前最為矚目的是GPU巨頭NVIDIA,但AI芯片計算需求不僅限于強于并行計算的GPU,還包括主打通用計算的CPU、專用芯片ASIC等。因此相關公司都在不斷攻堅提升芯片性能。
近日Arm高級副總裁兼基礎設施事業(yè)部總經理Mohamed Awad接受21世紀經濟報道等記者采訪時分析,目前在云服務商對AI的極大興趣驅動下,和AI相關的計算需求非常龐大,但傳統(tǒng)的通用CPU已無法滿足AI相關計算需求。而云服務商自主設計芯片過程中,也需要考慮這些芯片都能運行目前市面上已有的軟件。
“我們看到合作伙伴正構建與AI加速器緊密耦合的定制通用計算,這在Arm與NVIDIA Grace Hopper、亞馬遜云科技 (AWS) 以及微軟的合作中都有所體現(xiàn)。此外,這一趨勢也正發(fā)生在許多中國合作伙伴的項目上,他們在開發(fā)加速器的同時,還致力于協(xié)同設計通用計算。”他續(xù)稱。
從整體趨勢看,Arm 基礎設施事業(yè)部產品解決方案副總裁Dermot O’Driscoll指出,AI芯片行業(yè)正呈現(xiàn)兩個特征:其一,人們希望對支持云計算關鍵工作負載的計算進行優(yōu)化;其二,頭部企業(yè)正在打造定制芯片,并需要有效的方式來實現(xiàn)。
Mohamed Awad進一步分析,“基礎設施所需處理和管理的數(shù)據(jù)和計算量相當大,加上AI等新工作負載的計算需求又非常高。這意味著通用的現(xiàn)成芯片很難優(yōu)化到能夠支持基礎設施日益增長的需求。數(shù)據(jù)中心提供商和頭部云服務提供商正在重新設計整個服務器、機架和倉庫,從而獲得更佳的性能、效率和總體擁有成本 (TCO)。這一切驅使他們從定制芯片著手。”
他具體舉例道,在基礎設施領域,看到轉型持續(xù)朝向更復雜的倉庫級計算,它不再只關乎芯片、服務器或機架,而是關乎整個數(shù)據(jù)中心。
“NVIDIA就是很好的例子,其推出的Grace Hopper從根本上重新設計了系統(tǒng)架構。在這一設計中,從單個CPU管理多個GPU,轉變?yōu)镃PU與GPU一對一映射。更多CPU意味著內存一致性,最終會大大提高GPU的利用率。”他指出,AWS和微軟等巨頭也采取了類似方法,從頭開始設計系統(tǒng),并從定制系統(tǒng)級芯片 (SoC) 開始。因為他們比任何人都更了解自己的工作負載,可以對系統(tǒng)各方面進行調優(yōu),包括網絡、加速甚至是通用計算,以優(yōu)化效率、性能和TCO。
“去年我們推出了Arm Neoverse計算子系統(tǒng)(CSS),使定制芯片更迅速且易實現(xiàn)。”Dermot O’Driscoll介紹,在Neoverse CSS中,Arm負責配置、優(yōu)化和驗證一套完整的計算子系統(tǒng),并針對基礎設施市場的各種關鍵用例進行配置,從而讓合作伙伴能夠專注于針對特定系統(tǒng)級工作負載塑造差異化競爭優(yōu)勢,比如軟件調優(yōu)、定制加速等。此外,客戶還能加速產品上市時間、降低工程成本。
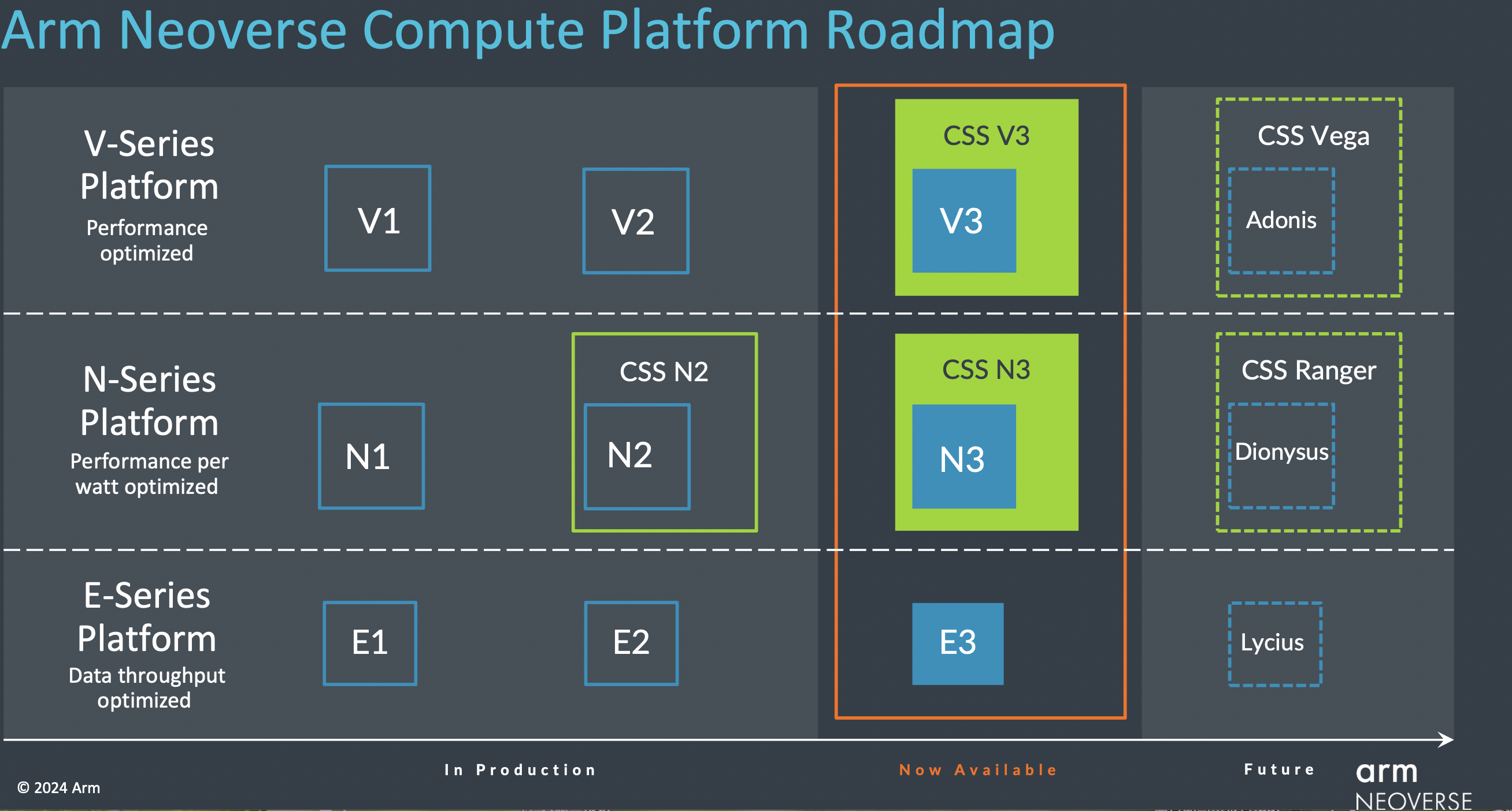
近期Arm宣布推出兩款基于第三代Neoverse IP構建的新Arm Neoverse CSS,即Arm Neoverse CSS V3和Arm Neoverse CSS N3。其中Arm Neoverse CSS V3與CSS N2相比,單芯片性能可提高50%;Arm Neoverse CSS N3與CSS N2相比,其每瓦性能可提升20%。
當然,AI的適用范圍不僅是應用服務器和數(shù)據(jù)中心。AI正成為包括網絡、安全和存儲等諸多領域不可或缺的一部分,它可應用到包括小型終端到交換機、路由器和基站等各種設備在內的整個基礎設施中。Mohamed Awad表示,憑借新的CSS N3和CSS V3,Arm專注于釋放芯粒等新技術的潛力,并更大限度優(yōu)化實際工作負載的TCO。
當然也正因為自研芯片參與者眾多,導致相關AI芯片從設計、流片到最終商用落地的過程,將涉及與不同軟件、接口等匹配,同時如何節(jié)省能耗也尤為重要。
Dermot O’Driscoll受訪時介紹,在算力需求持續(xù)增長下,意識到算力也受到成本和能源的限制這一點很重要。這也驅動了在數(shù)據(jù)中心和基礎設施中自上而下的優(yōu)化,并帶來越來越多專為軟件工作負載量身打造定制芯片的需求。
“在構建Neoverse N3和V3平臺時,Arm也與合作伙伴緊密合作,了解他們的軟件需求并針對這些需求提供優(yōu)化。我們的CSS和IP平臺意味著合作伙伴可以更加靈活地根據(jù)特定需求進一步優(yōu)化設計。”他續(xù)稱,“同時,我們一直在與合作伙伴一起構建和優(yōu)化云原生軟件。我們從早期就將軟件棧和工作負載遷移到Arm平臺的合作伙伴那里,得到的反饋是,整個遷移過程比預期容易。”
在應用場景方面也有新的趨勢表現(xiàn)。Dermot O’Driscoll分析道,目前行業(yè)重點更多放在訓練LLM(大語言模型)上,但隨著生成式AI廣泛應用于實際業(yè)務場景,其工作重點將轉向推理。有分析師估計,已部署的AI服務器中有高達80%專用于推理,這一數(shù)字還將持續(xù)攀升。
近期NVIDIA財報會上也提到,在去年第四財季,其數(shù)據(jù)中心類業(yè)務中,約有40%收入是用于AI推理所產生。
這一轉變意味著要找到合適的模型和模型配置,并加以訓練,然后將其部署到更具成本效益的計算基礎設施上。吞吐量是其中一部分考慮因素,當然還有其他因素。
Dermot O’Driscoll表示,CPU廣泛可用,并可靈活用于ML(機器學習)或其他工作負載,此外,CPU還易于部署,并可支持各種軟件框架,具備低成本和高能效等優(yōu)勢。因此,CPU推理將是生成式AI計算應用的關鍵組成。但顯然,也并非所有AI處理都將在CPU上進行。
“NVIDIA Grace Hopper的一大關鍵創(chuàng)新在于內存容量和共享內存模式。這種緊耦合的CPU加上加速器配置,對大參數(shù)LLM非常有益,對檢索-增強-生成 (RAG) 等新興方法也很有幫助。Arm推出的Neoverse CSS能提供客戶所需的所有接口,以便選擇耦合自身的加速器。這種方法既可以在需要CPU時提供CPU,又可以在需要AI加速器時提供AI加速器,做到兩全其美。”他指出。
在Neoverse CSS基礎上,去年10月,Arm全面設計(Arm Total Design) 生態(tài)項目推出,圍繞Arm計算子系統(tǒng)開展創(chuàng)新設計。Arm基礎設施事業(yè)部營銷副總裁Eddie Ramirez則介紹,在推出后四個月內,Arm全面設計生態(tài)項目已有20多家成員加入。其中包括新的EDA和配套IP提供商以及來自各個戰(zhàn)略市場的芯片設計合作伙伴。
轉載來源:21世紀經濟報道 作者:駱軼琪
 分享
分享

 京公網安備 11010802028547號
京公網安備 11010802028547號
 購物車
購物車





